
Discover how web app scalability explained can boost your team's growth. Master essential architectural principles for seamless performance!
TL;DR:
- Web app scalability ensures performance and reliability as user demand grows by leveraging architectural techniques.
- Key strategies include stateless design, layered caching, horizontal scaling, and automation through tools like Kubernetes.
Web app scalability is the architectural capability that lets a web application maintain performance and reliability as user demand increases. Growth-stage companies hit this wall fast. One viral moment, one product launch, one enterprise client, and suddenly your infrastructure is the bottleneck. Web app scalability explained properly means understanding five compounding layers: stateless design, caching, CDN, async processing, and database read/write splitting. Get these right in sequence and you can move from hundreds to millions of users without rewriting your entire codebase. This guide walks through the architecture, the tradeoffs, and the mistakes that cost teams months of rework.
What core architectural principles enable web app scalability?
Stateless design is the single most important foundation for scalable web applications. A stateless service processes each request independently, with no memory of previous interactions stored on the server itself. Implementing stateless services requires offloading session state to external stores like Redis or using token-based auth (JWT) so any instance can handle any request interchangeably. This is what makes horizontal scaling possible in the first place.
Loosely coupled services are the second pillar. When your application is one large monolith, scaling one component means scaling everything. Service-oriented architecture (SOA) and microservices solve this by decomposing your app into independent units that deploy and scale individually. A spike in your image processing service does not drag down your authentication service. Fault isolation becomes real, not theoretical.
Here is what stateless, decoupled architecture enables in practice:
- Independent scaling: Each service scales based on its own load, not the load of the whole system.
- Failure isolation: One service going down does not cascade across the entire application.
- Parallel deployments: Teams can ship updates to individual services without coordinating a full release.
- Load distribution: Load balancers distribute traffic efficiently across multiple stateless instances, improving availability and reliability.
- Faster recovery: Stateless instances restart cleanly with no corrupted session data to untangle.
Pro Tip: Start with stateless design before you write your first line of business logic. Retrofitting statelessness into an existing stateful app is one of the most expensive architectural refactors a team can face.
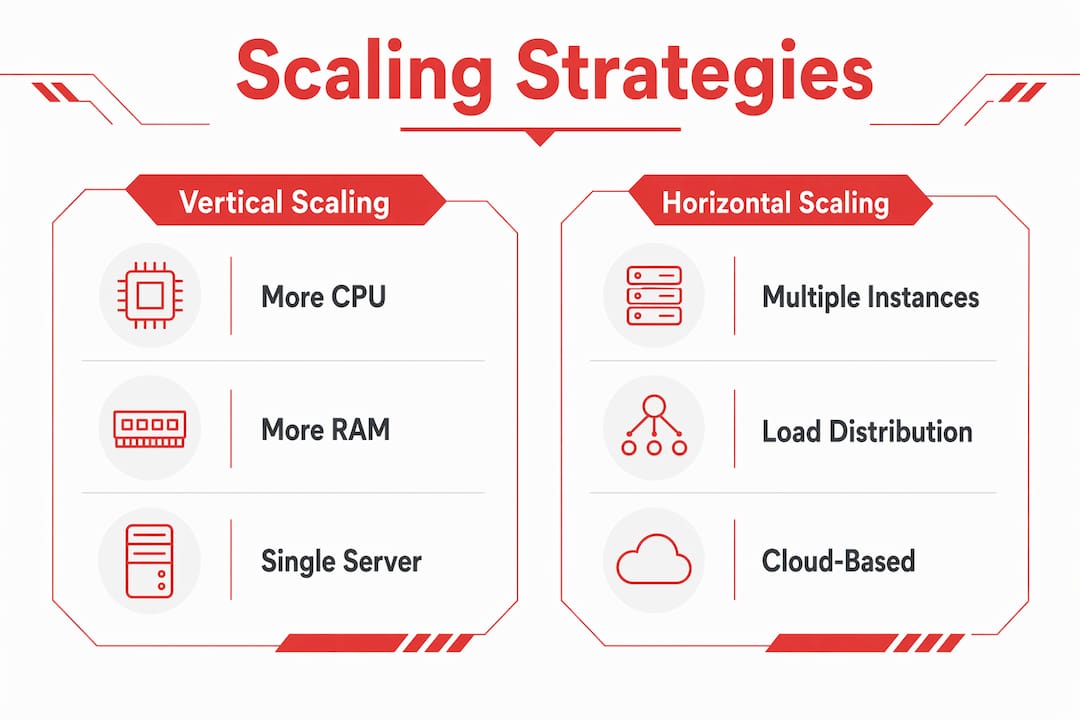
Vertical vs. horizontal vs. diagonal: which scaling strategy fits?
Vertical scaling means adding more CPU or RAM to a single server. It is fast to implement and requires no code changes. The problem is physical ceilings. Every server has a maximum configuration, and when you hit it, you have a single point of failure with no redundancy. Vertical scaling hits limits that horizontal scaling does not.
Horizontal scaling adds more smaller instances and distributes load across them. This is the standard approach in modern cloud-native architecture. When one instance fails, it represents only a fraction of total capacity rather than 100% downtime. Netflix and Zoom both rely on horizontal scaling to serve global user bases. The tradeoff is added complexity in coordination, state management, and load distribution.

Diagonal scaling combines both approaches. You vertically optimize each instance to a cost-effective configuration, then scale horizontally as demand grows. This gives you the performance benefits of larger instances without betting everything on a single server.
| Attribute | Vertical Scaling | Horizontal Scaling | Diagonal Scaling |
|---|---|---|---|
| Capacity ceiling | Hard physical limit | Near-infinite | High, with optimization |
| Resilience | Single point of failure | Failure isolated to 1/N | High resilience |
| Complexity | Low | Medium to high | Medium |
| Cost behavior | Steep at upper limits | Linear with demand | Balanced |
| Best for | Early-stage, simple apps | High-traffic, distributed | Growth-stage companies |
Pro Tip: If you are on AWS, GCP, or Azure, start horizontal from day one. Cloud pricing makes large single instances expensive fast, and you will need the redundancy anyway when you start signing enterprise SLAs.
What multi-layered techniques power scalability beyond raw compute?
Raw compute scaling alone does not get you to millions of users efficiently. The real leverage comes from reducing the work your servers have to do in the first place. Building for scale requires five compounding layers that work together to absorb demand before it ever hits your core infrastructure.
Here is how those layers stack in practice:
- Multi-tier caching: Redis and in-memory caches absorb 80–95% of read traffic before it reaches your database. This single layer has more impact on perceived performance than any hardware upgrade.
- CDN distribution: Content delivery networks like Cloudflare or AWS CloudFront push static assets and cached responses to edge nodes close to your users. Latency drops. Origin server load drops.
- Asynchronous processing: Background job queues (RabbitMQ, AWS SQS, BullMQ) offload non-critical tasks like email sending, report generation, and image resizing. Your API responds fast; the heavy work happens later.
- Database read replicas: Splitting reads to replica instances and writes to a primary reduces contention on your main database. This is the right move before you consider sharding.
- Database sharding: Sharding splits data across servers to scale writes, but adds real complexity in query routing and data consistency. Do this last, not first.
| Layer | Primary Benefit | When to Add It |
|---|---|---|
| Redis caching | Absorbs 80–95% of reads | Before database scaling |
| CDN | Reduces latency and origin load | At launch for static assets |
| Async queues | Frees API threads for live requests | When response times degrade |
| Read replicas | Reduces DB read contention | Before sharding |
| Sharding | Scales write throughput | After all other layers are optimized |
The compounding effect here is real. Each layer you add multiplies the capacity of the layers beneath it. A well-cached application with a CDN in front of it can handle 10x the traffic with no changes to compute.
How does autoscaling help manage dynamic web app loads?
Autoscaling automatically adjusts compute resources based on real-time demand. Autoscaling ensures performance during spikes and cost efficiency during low-traffic periods. Netflix spins up hundreds of instances nightly to meet peak demand, then scales back down. That is not manual ops work. That is infrastructure automation.
Kubernetes is the dominant platform for container orchestration at scale. Kubernetes organizes containerized applications into manageable units and handles automatic scaling, failover, rolling updates, and resource optimization without increasing operational complexity. Horizontal Pod Autoscaling (HPA) watches CPU and memory metrics and adds or removes pods in response.
Key capabilities autoscaling and Kubernetes give you:
- Horizontal Pod Autoscaling: Scales pod count based on CPU, memory, or custom metrics like request queue depth.
- Rolling updates: Deploy new versions with zero downtime by gradually replacing old pods with new ones.
- Self-healing: Kubernetes restarts failed containers and reschedules pods away from unhealthy nodes automatically.
- Resource limits: Set CPU and memory ceilings per pod to prevent one runaway process from starving the rest of the cluster.
- Cloud-native elasticity: Cloud providers like AWS (EKS), Google (GKE), and Azure (AKS) manage the underlying node infrastructure so you focus on application logic.
Pro Tip: Set autoscaling thresholds based on observed traffic patterns, not guesses. Use tools like Datadog or Prometheus to collect baseline metrics for two to four weeks before configuring your first autoscaling rules.
What pitfalls should growth-stage companies avoid when scaling?
Scaling is a process tailored to specific bottlenecks, not a template you copy from a larger company. The most expensive mistakes come from applying the wrong solution to the wrong problem at the wrong time.
Common pitfalls that cost teams months of rework:
- Premature database sharding: Many developers scale databases too early before caching is optimized. Redis absorbing 80–95% of reads often eliminates the need for sharding entirely at growth-stage traffic levels.
- Monolithic architecture: A single deployable unit cannot scale individual components. When your checkout service needs 10x capacity, you scale everything or nothing.
- Ignoring statelessness: Stateful servers create sticky sessions that break load balancing. Every instance needs to handle every request, or your load balancer becomes a liability.
- Copying large-scale architectures blindly: What works for Google or Amazon at billions of requests per day adds unnecessary complexity at 100,000 requests per day. Match your architecture to your actual load.
- Skipping observability: You cannot fix a bottleneck you cannot see. Monitoring tools like Datadog, New Relic, or open-source options like Grafana with Prometheus are not optional at growth stage.
“Identifying your true bottleneck is the most important step in effective scaling. Compute, database I/O, and network latency each require completely different solutions.”
Iterative capacity planning beats big-bang infrastructure overhauls every time. Measure, identify the constraint, fix it, and measure again. That loop is the actual practice of scaling.
Key takeaways
Scalable web applications require stateless architecture, layered caching, and horizontal scaling to handle growth without full rewrites.
| Point | Details |
|---|---|
| Start with stateless design | Offload session state to Redis or JWT tokens so any instance handles any request. |
| Layer your scaling approach | Caching, CDN, and async queues reduce server load before you add more compute. |
| Prefer horizontal over vertical | Horizontal scaling provides near-infinite capacity and eliminates single points of failure. |
| Use autoscaling with real metrics | Configure Kubernetes HPA thresholds based on observed traffic, not assumptions. |
| Fix bottlenecks in sequence | Identify whether compute, DB I/O, or network latency is the constraint before scaling anything. |
What i have learned building scalable systems for growth-stage teams
The conventional advice is to “design for scale from day one.” I think that framing sends teams in the wrong direction. It makes people over-engineer early infrastructure when they should be shipping product.
What actually works is designing for statelessness from day one. That is a much smaller, more specific commitment. It means you do not store session data on your servers. It means your services do not assume they know what happened in the last request. That one discipline unlocks everything else when you need it.
The teams I have seen struggle most are the ones who built a fast monolith, grew into it, and then tried to decompose it under production load. That is genuinely painful work. The teams who built loosely coupled services early, even simple ones, had a much easier time adding capacity when traffic spiked.
The other thing worth saying: cloud automation is powerful, but observability is what makes it trustworthy. Autoscaling without monitoring is just automated chaos. You need to know what your system is doing before you let it make decisions on its own. Tools like Datadog and Prometheus are not overhead. They are the feedback loop that makes everything else work.
Check out Rule27design’s thinking on scalable digital tools if you want more context on how these architectural decisions connect to business outcomes at the growth stage.
— Josh
Ready to build infrastructure that actually scales?
Rule27design works with growth-stage companies that have outgrown basic tools but are not ready for enterprise complexity. The Innovation Lab is where we design and build custom digital infrastructure: admin panels, internal tools, and backend systems architected for the load you are heading toward, not just the load you have today.
Our tech stack includes React, Supabase, and Node.js, and we are platform agnostic. We pick the right tool for your specific system. If you are hitting performance walls or planning a scaling push, we can help you sequence it correctly. Explore the Innovation Lab or reach out directly to talk through your architecture.
FAQ
What is web app scalability?
Web app scalability is the ability of a web application to maintain performance as user demand increases by efficiently managing resources and load. It involves architectural decisions like stateless design, caching, and horizontal scaling.
What is the difference between horizontal and vertical scaling?
Vertical scaling adds CPU or RAM to a single server, while horizontal scaling adds more instances and distributes load across them. Horizontal scaling provides near-infinite capacity and eliminates single points of failure.
Why is caching so important for scalable web apps?
Multi-tier caching with tools like Redis absorbs 80–95% of read traffic before it reaches your database. This reduces database load dramatically and delays the need for costly database sharding.
When should a growth-stage company start thinking about scalability?
Stateless design and loose service coupling should be built in from the start. Caching, CDN, and autoscaling layers can be added incrementally as traffic grows and specific bottlenecks are identified.
What is kubernetes and why does it matter for scaling?
Kubernetes is a container orchestration platform that automates scaling, failover, rolling updates, and resource management for containerized applications. It enables growth-stage teams to manage dynamic loads without proportional increases in operational overhead.

About the Author
Josh AndersonCo-Founder & CEO at Rule27 Design
Operations leader and full-stack developer with 15 years of experience disrupting traditional business models. I don't just strategize, I build. From architecting operational transformations to coding the platforms that enable them, I deliver end-to-end solutions that drive real impact. My rare combination of technical expertise and strategic vision allows me to identify inefficiencies, design streamlined processes, and personally develop the technology that brings innovation to life.
View Profile

